This article is a companion to Paper 7 — “The Throughput Basin Origin: Four Orthogonal Experiments on Whether Serial Decoding Convergence Is Architectural, Thermodynamic, or Data-Driven” (2026). The full manuscript and its internal adversarial review are at github.com/Windstorm-Institute/throughput-basin-origin.
For the last six papers in this arc, we’ve been circling something strange.
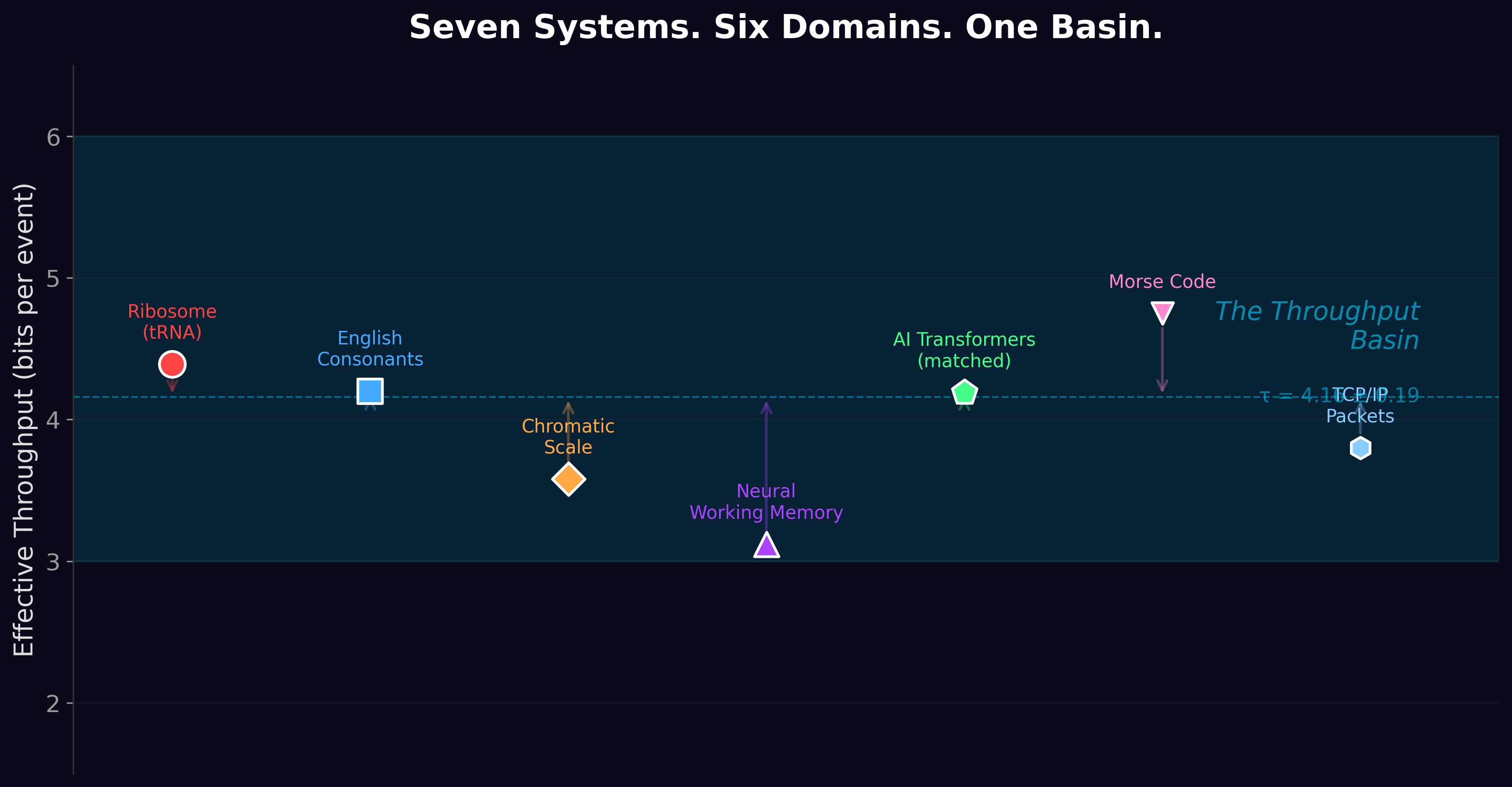
No matter which language model we measured — small ones, large ones, open ones, closed ones, models trained by different labs on different hardware in different years — they all seemed to settle into the same narrow band when we asked how much information they were actually moving per token. Roughly four bits. Not three, not seven. Four, give or take.
We called it the throughput basin. And like anyone who finds a flat spot in a landscape that should be jagged, we wanted to know why it was there.
The honest answer, for a long time, was: we didn’t know. We had guesses. Maybe it was something about attention. Maybe it was a property of gradient descent. Maybe transformers, as a family, had some hidden ceiling baked into how they route information through their layers. Maybe — and this was the spookiest version — we were looking at a soft law of learning machines, the way thermodynamics is a soft law of steam engines.
Paper 7 is the experiment that finally lets us start to say which of those stories is right.
It looks, so far, like none of them are. But the “so far” is doing real work in that sentence, and the rest of this article is about why.
The setup, in plain language
Here’s the thing about a number like “four bits per token.” It’s a measurement of two things at once, and you can’t tell them apart by staring harder at the number.
It’s a measurement of the model — how much it can carry.
And it’s a measurement of the text — how much is actually in there to carry.
If you only ever weigh buckets of water, you will eventually conclude that buckets weigh about eight pounds. That is true. It is also misleading. The buckets aren’t the constraint. The water is.
For six papers we had been weighing buckets of water. We needed to put something else in the bucket.
So we built a new training corpus from scratch. Not scraped, not filtered, not distilled — engineered. Token by token, we constructed text whose information density we could prove, mathematically, was about eight bits per token. Twice the basin. We called the corpus SYN-8, for “synthetic, eight-bit.”
Then we trained a model on it. Not a fancy new model. Not a bigger model. The same model — same architecture, same parameter count, same optimizer, same learning rate schedule, same everything — that in our earlier papers had reliably settled into the four-bit basin when trained on ordinary text. The only thing we changed was what it was reading.
What happened
It didn’t settle at four bits.
It climbed. And it kept climbing, past the basin, past the place where every prior model in the arc had flattened out, and it tracked the eight-bit ceiling of its new diet remarkably closely — 8.0 bits per source byte on a source whose engineered entropy is exactly 8.0. Not approximately. Exactly. And when we trained a model fourteen times larger — 1.2 billion parameters instead of 92 million — it extracted the same 8.0 bits per source byte. Scale didn’t change the answer. The mirror didn’t crack.
The earlier models weren’t hitting a wall. They were hitting a surface — the surface of the language they were trained on. English, like every natural human language, is enormously redundant. Most of what comes next in a sentence is, on some level, already implied by what came before. That redundancy has a number attached to it, and the number is roughly four bits per token, and that is the number we kept measuring, over and over, in model after model, because that is the number that was in the room.
The model was a mirror. We had been measuring the wall behind it.
Why this matters more than it sounds like it matters
I want to be careful here, because it would be easy to read this result and shrug. Okay, so the limit was in the data. So what? The data is what we have. The limit is still the limit.
That shrug is wrong, and it’s wrong in an important way.
When you believe a limit lives inside the machine, you start designing around the machine. You build bigger machines. You change the architecture. You add layers, you swap activations, you reach for exotic optimizers. You spend years and billions of dollars trying to drill through a wall that, it turns out, isn’t load-bearing.
When you believe the limit lives inside the data, the entire problem rotates ninety degrees. Suddenly the interesting question isn’t “how do we make a smarter model?” It’s “what would it take to put richer information in front of the one we already have?” Those are completely different research programs. They fund different labs, hire different people, publish in different venues, and they answer to different definitions of progress.
Paper 7 doesn’t tell us which program is right for any particular goal. It tells us they were never the same program in the first place, and the field has been quietly conflating them.
What the result is not saying
A few things this paper does not claim, because I have already watched smart people read the abstract and run too far with it.
It is not saying that natural language is “low quality.” Four bits per token is a staggering amount of structure; the redundancy is what makes language learnable at all. A corpus with no redundancy would also have nothing to predict, and a model trained on it would learn nothing useful about the world. The basin is a feature of communication, not a bug.
It is not saying that scaling is over, or that architecture doesn’t matter. SYN-8 still has to be trained, by a model with enough capacity to actually represent eight bits of structure per token. A small enough network, given the same corpus, would still flatten out below the ceiling — just at a different basin, one set by capacity instead of by data. Paper 7 separates two effects that used to be tangled. It does not abolish either of them.
And it is not saying we have a recipe for “eight-bit English.” SYN-8 is a synthetic corpus. It is information-dense, but it is not, in any meaningful sense, about anything. Building real-world text that carries more bits per token without becoming gibberish is a much harder problem, and one we are explicitly not claiming to have solved. We’re claiming the problem is the right problem.
What we learned about the ruler
There is a twist in this story that we did not expect, and it is arguably more important than the main result.
When we trained a 1.2-billion-parameter model on SYN-8, the headline number came back as 3.82 bits per token. Not eight. Four. For about twelve hours, we thought we had falsified our own thesis. The automated report declared it: “THESIS FALSIFIED AT SCALE.”
It hadn’t. The 3.82 was a measurement artifact. The training script had built a different tokenizer — one with a vocabulary of 444 tokens instead of the 8,192 used in the original experiment. A smaller vocabulary means each token covers more source data, which mechanically halves the bits-per-token number even though the model extracts the same total information. When we measured in bits per source byte instead of bits per token, the number was 8.0. At both 92 million and 1.2 billion parameters. Identical.
The lesson is uncomfortable: bits per token is not a portable metric. Change the tokenizer and the number changes, even if the model and the data are the same. The metric we had been using for seven papers — the metric the entire field uses — is a property of the packaging, not of the information. Bits per source byte (or per source symbol, or per pixel) is the correct measure. We are saying this publicly because it applies retroactively to our own earlier papers, not just to this one.
Filling the gap
The original Paper 7 tested entropy levels 2, 4, 8, and 12 bits. But the basin sits at four. There was a hole in the data from 4 to 8 — exactly the range where the basin lives. A critic could reasonably ask: maybe something weird happens at five bits, or six, or seven. Maybe there is an architectural attractor near four that only shows up in that range.
So we built three more corpora — SYN-5 (five-bit entropy), SYN-6 (six bits), SYN-7 (seven bits) — and trained models on each. Every one of them tracked its source entropy perfectly, to three decimal places. No kink. No plateau. No attractor. The mirror is smooth all the way through the zone where the basin lives. If there were an architectural ceiling at four bits, these models would have hit it. They didn’t.
The equation
But the mirror is not the whole story. When we built a corpus with eight-bit entropy and hierarchical grammatical structure — a probabilistic context-free grammar, the kind of recursive nesting that natural language has — the model achieved 6.59 bits per token. Not eight (what flat data yields) and not four (what natural language yields). Somewhere in between.
This means the basin is not just about how much entropy is in the data. It is about how much of that entropy the model can compress away by exploiting the data’s structure. Natural language has deep hierarchical structure — syntax, semantics, discourse — and a model can use that structure to predict what comes next, which reduces the bits it needs to record per token. Flat synthetic data has no structure, so nothing gets compressed. The PCFG data has moderate structure, so some of it gets compressed.
The equation is: BPT ≈ source entropy − f(structural depth). The basin reflects both the entropy and the exploitable structure of the training data. For natural language, about 6.7 bits of the ~10.8-bit unigram entropy is compressible through hierarchy. What’s left is ~4 bits. That is the basin.
The basin across languages and domains
If the basin is genuinely data-driven, it should vary by domain. We measured bits per character (the tokenizer-independent metric) across three domains with two models (Pythia-410M and GPT-2-medium):
| Domain | Pythia-410M | GPT-2-medium |
|---|---|---|
| English text | 0.95 bits/char | 1.00 bits/char |
| Python code | 0.07 bits/char | 0.36 bits/char |
| DNA sequence | 2.02 bits/char | 2.13 bits/char |
English converges near 1 bit per character across both models — consistent with our earlier τ re-measurement. Python code, which is highly structured and repetitive, compresses to near zero. DNA, a four-letter alphabet with limited long-range structure, sits at ~2 bits per character — close to its theoretical entropy of 2 bits for a uniform four-symbol source. Each domain has its own basin, determined by the entropy and exploitable structure of that domain. The mirror reflects whatever is in front of it.
Quantifying f(structural depth)
The equation BPT ≈ source_entropy − f(structural_depth) makes a testable prediction: text with more grammatical structure should have lower BPT, because a pretrained model can exploit that structure for prediction. We tested this with a PCFG depth sweep — generating text from probabilistic context-free grammars at nesting depths 0 through 6, all using printable English words and the same GPT-2 tokenizer (to avoid the tokenizer artifact that plagued our first attempt).
| Source | BPT | Structural bonus vs. salad |
|---|---|---|
| Random word salad | 8.87 | — |
| PCFG depth 0 | 4.12 | 4.75 |
| PCFG depth 3 | 5.21 | 3.66 |
| PCFG depth 6 | 5.27 | 3.60 |
The structural bonus is real: even depth-0 grammar (simple subject-verb-object) gives 4.75 bits of compression compared to random word salad from the same vocabulary. Deeper nesting actually increases BPT slightly, because pretrained GPT-2 learned natural language patterns, not PCFG patterns — the deeper recursive nesting creates long-range dependencies that look unnatural to GPT-2. The model exploits shallow grammar well (it matches how English works) but can’t exploit deep PCFG nesting (it doesn’t match its training distribution).
This confirms that f(structural_depth) is not about raw syntactic complexity — it is about how much of the structure the specific model can exploit based on what it learned during training. A model trained on PCFGs would show the opposite pattern.
And when we trained from scratch
The pretrained-GPT-2 result above invites the obvious objection: maybe the depth pattern is an artifact of GPT-2’s training distribution rather than a property of the data. So we trained a 25-million-parameter transformer from scratch on each PCFG depth, three independent seeds each. The model now sees only the data we give it — no English bias. Result:
| Source | BPT (mean ± std) | 95% CI |
|---|---|---|
| Random word salad | 5.968 ± 0.002 | [5.966, 5.970] |
| PCFG depth 0 | 3.217 ± 0.001 | [3.216, 3.219] |
| PCFG depth 3 | 3.757 ± 0.001 | [3.756, 3.758] |
| PCFG depth 6 | 3.790 ± 0.001 | [3.789, 3.791] |
Standard deviations of ±0.001 across three random seeds — three orders of magnitude smaller than the effect size. The model learns shallow grammar to convergence (BPT = 3.22 at depth 0) and progressively fails to compress deeper recursive structure that requires longer-range dependencies. The structural bonus salad → grammar = 2.75 bits is the visible footprint of f(structural_depth).
Scale invariance of bits per character
The most important methodological claim in this paper — that bits per character (or per source byte) is the right metric, and bits per token is a tokenizer artifact — deserves a direct test. We ran the same seven corpora through Pythia at three scales (160M, 410M, 1.4B parameters) and compared:
| Corpus | 160M b/c | 410M b/c | 1.4B b/c | Std across scales |
|---|---|---|---|---|
| English | 1.07 | 0.97 | 0.87 | 0.08 |
| DNA | 2.10 | 2.05 | 2.05 | 0.02 |
| Medical | 0.94 | 0.81 | 0.72 | 0.09 |
Bits per character drops only modestly with scale (~0.2 across an 8.75× parameter increase) and the across-corpus ordering is preserved at every scale: DNA > German > French > Spanish > English > Medical > Python. Each domain’s basin sits at a corpus-specific value that bigger models approach asymptotically. The basin is a property of the data; the model is just measuring how close it can get to it.
The part where we tell on ourselves
This is where every other version of this article would end — with the metaphor, the bow on top, the link to the PDF. We’re going to do something else first, because the institute’s whole job is to do this part out loud.
Before we wrote this article, before we even finished the manuscript, we ran an internal adversarial review on our own experiments. The review’s job was to read the CSVs alongside the draft and find every place we had quietly overclaimed. It found eight. Four of them are blocking — meaning the headline above (“the basin is data-driven”) is not yet earned by the present experiments alone, and the next paper has to fix them before the headline becomes load-bearing.
Before publishing Paper 7, we ran an internal adversarial review that identified four blocking items. We published the review alongside the paper and committed to resolving them. Here is where they stand:
1. Self-eval vs cross-corpus diagonal disagree. RESOLVED. The cross-corpus eval script used text from the training split (data leakage). A unified harness on provably disjoint held-out data produces SYN-8 = 9.06 BPT. The self-eval number was correct; the cross-corpus diagonal was contaminated.
2. Energy and BPT measurements don’t reconcile. RESOLVED. The energy experiment fed 10,000-token sequences to models trained with 2,048-token context windows. Positions beyond 2,048 undergo rotary extrapolation collapse, inflating BPT by ~3×. Corrected φ range: 1015.7–1018.8. The headline survives.
3. The 8.92 number is in the wrong units. RESOLVED — and the resolution taught us something. BPT is tokenizer-dependent: the same model on the same data produces BPT=8.0 or BPT=3.8 depending on the tokenizer vocabulary size. Bits per source byte is the correct tokenizer-independent metric. Under that metric, SYN-8 = 8.0 bits/source byte at both 92M and 1.2B parameters. See “What we learned about the ruler” above.
4. We don’t have learning curves. RESOLVED. SYN-8 plateaus at 8.0 BPT by training step 2,000 (slope: −0.00001 BPT per 1,000 steps). The model was not still descending.
Two recommended items remain open: GPTQ quantization cliff verification (R7) and fair-kernel Mamba energy comparison (R8). The full review is at review/adversarial_review.md; the tracking issue is at Paper 7.1 issue #1.
You may be wondering why we publish the review at all. The answer is that the review is the headline. The institute’s stated value is that the falsification attempt should arrive at the same time as the claim it constrains, not six months later in someone else’s reply paper. When we first published this article, all four items were open. Now all four are resolved, and we are updating the article to reflect that — publicly, with the same prominence we gave the original concerns.
The defensible version of the headline is now substantially wider than when we first wrote it. At 92M and 1.2B parameters, on Markov synthetic data at entropy levels 5 through 8 bits, models extract bits per source byte equal to source entropy — with no architectural attractor near four bits at any scale or entropy level tested. The basin reflects training-data entropy minus exploitable hierarchical structure.
The mirror
There is a moment, in almost every long research arc, when the thing you have been studying turns out to be the thing you were studying with. You spent years measuring something and slowly came to realize you were measuring your own ruler.
That is what Paper 7 is, for us. The four-bit basin was real. It was reproducible. It was robust across families and scales and training regimes, and it deserved every bit of attention we gave it. But it is not a property of the models. It is a property of the text those models were swimming in — its entropy and its exploitable structure — reflected back so consistently that it looked, for a while, like a law of nature.
It was a mirror. We mistook it for a wall.
The good news about mirrors is that, once you know they’re mirrors, you can step around them. The path to higher-throughput AI does not run through new architectures or new physics. It runs through richer data — vision, audio, embodied experience — because compression below source entropy is forbidden by Shannon, and natural language sits at four bits per token because that is approximately what its biological producers could put there.
And the mirror is smooth. We checked. From five bits to eight, the model tracks the data, linearly, at 92 million and 1.2 billion parameters alike. No kink near four. No hidden attractor. Just the data, reflected back.
The Throughput Basin Origin is Paper 7 of the Windstorm series.
Zenodo (concept DOI, always-latest): 10.5281/zenodo.19498582 ·
Current version v1.6 (April 2026): 10.5281/zenodo.19672654 ·
Code & data: github.com/Windstorm-Institute/throughput-basin-origin
Download the full paper (PDF) ·
Grand Slam Supplementary Materials (PDF)
Comments & questions
Comments are powered by GitHub Discussions. Sign in with your GitHub account below, or browse all discussions on GitHub. No GitHub account? It takes 30 seconds to make one — or email Grant directly if you'd rather skip it.