This article summarizes “The Inherited Constraint: Biological Throughput Limits Shape the Information Structure of Human Language and, Through It, AI” (2026).
The Dissipative Decoder proved that silicon AI has no thermodynamic throughput basin. Its energy scales sub-linearly with model capacity. No quadratic discrimination cost. No efficiency peak. No physical speed limit.
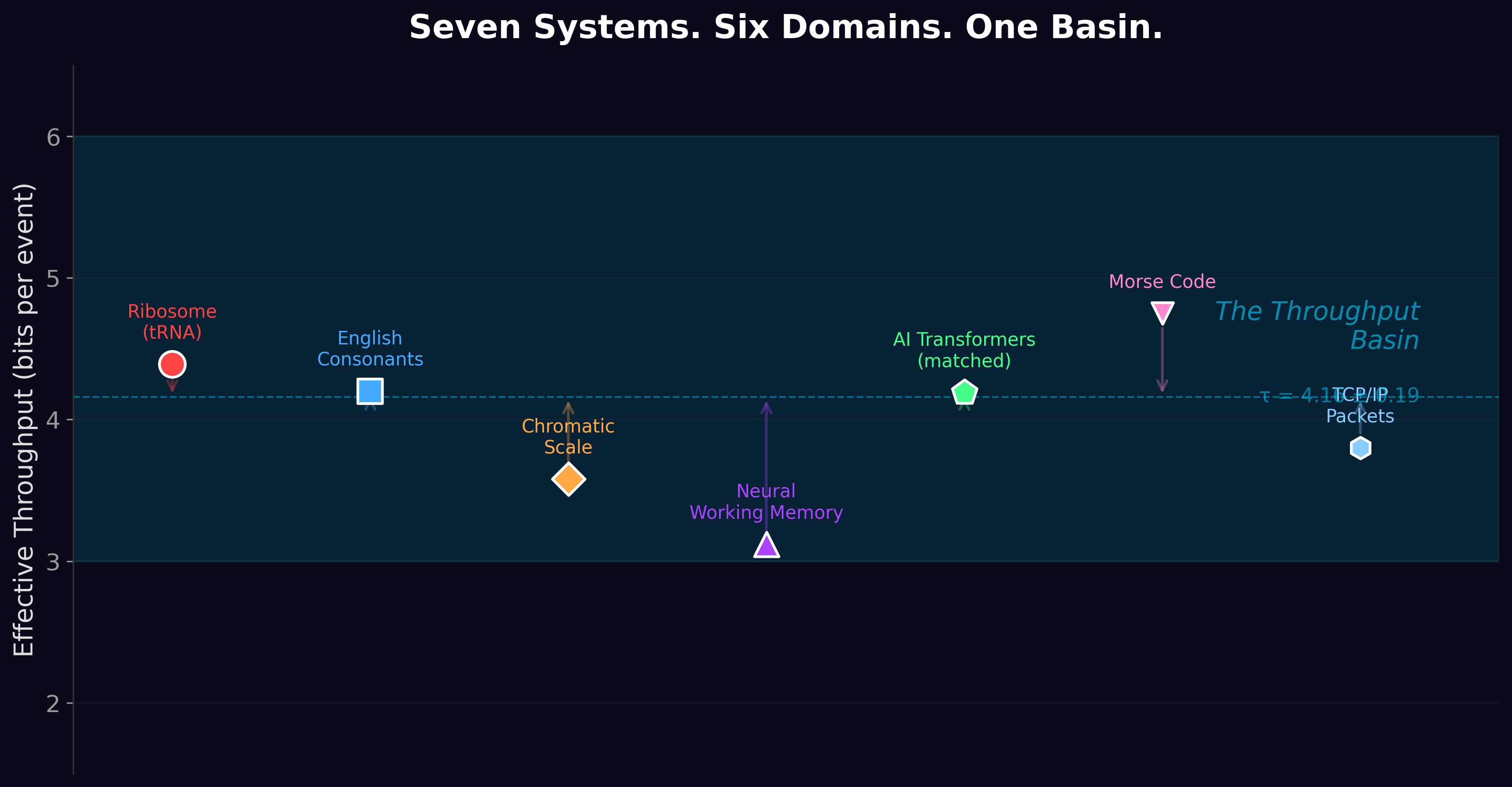
And yet AI models converge on ~4.2 bits of effective information per token — right in the middle of the biological basin that they are supposedly exempt from.
This is the paradox. If the physics doesn’t constrain silicon, why does silicon land in the same neighborhood as the ribosome?
The Hypothesis
AI inherits its throughput from the biological systems that generated its training data.
Every language model ever built was trained on human text. Human text was written by human brains. Human brains are biological serial decoders constrained by the throughput basin. The information density of human language — how surprising each word is, how predictable each sentence is — evolved to match the ~4–5 bit processing capacity of the biological systems that produce and receive it.
When GPT-4 processes English at ~4.4 bits per token, it is not obeying a law of silicon physics. It is learning a pattern that biological evolution burned into the structure of language over millions of years.
The Experiment
We measured bits-per-token (BPT) — the model’s average surprise at each word — across seven types of data. Four models. Same hardware. Same methodology. We computed all BPT values before comparing them to the biological basin. If natural language had shown 2 bits or 9 bits, we would have reported that. This is a basin-blind design.
It showed 4.4 bits.
The ribosome processes information at 4.39 bits per codon. Claude Shannon, in 1951, estimated the entropy of printed English at approximately 1 bit per character — roughly 5 bits per word. Three independent measurements, three different methods, three different decades, the same number.
The Seven Corpora
| Corpus | Bits per Token | What It Tells Us |
|---|---|---|
| Natural language (English prose) | 4.4 | In the basin. Matches the ribosome. |
| Programming code (Python) | 2.8 | Below the basin. More predictable than prose. |
| DNA sequences | 4.5 | In the basin — but a tokenizer artifact. |
| Synthetic structured data | 3.9 | In the basin — models exploit any pattern. |
| Mathematical notation | 7.5 | Above the basin. Unfamiliar to the model. |
| Random printable text | 8.5 | Far above. No patterns to exploit. |
| Shuffled English (same words, random order) | 10.8 | Far above. Structure destroyed. |
The most important row is the last one. Shuffled English uses the exact same words as regular English. Same vocabulary. Same word frequencies. Same Zipf distribution. But the grammar, syntax, and semantics have been destroyed — words appear in random order.
Without structure, per-token surprise more than doubles. The model can no longer predict what comes next because the cognitive organization of language is gone. What remains — raw word frequencies — is not enough.
Where Structure Lives: The Granular Shuffling Cascade
We didn’t just shuffle all the words at once. We destroyed structure one level at a time, measuring the information loss at each step:
Shuffle paragraphs (keep sentences intact): lose ~1.3 bits. Discourse-level structure — how paragraphs connect to each other — carries about 1.3 bits of information per token.
Shuffle sentences (keep words intact within each sentence): lose another ~0.6 bits. Sentence ordering — which sentence follows which — carries about 0.6 bits.
Shuffle words within sentences (keep sentence boundaries): lose ~3.3 bits. This is the big one. Sentence-internal word order — syntax — carries 3.3 bits of information. More than discourse, sentence ordering, and every other level combined.
Shuffle all words (destroy everything): lose another ~1.0 bit. The remaining word-order effects within the previous level.
Syntax — the grammar of how words are arranged within sentences — is the dominant carrier of cognitive information in human language. Not the vocabulary. Not the paragraph structure. Not the topics or themes. Grammar.
This finding connects to a 15-year-old hypothesis in psycholinguistics called Uniform Information Density (Jaeger, 2010; Levy & Jaeger, 2007). UID proposes that speakers distribute information roughly evenly across words to match the receiver’s processing capacity. But UID never specified what that capacity IS. The throughput basin provides the missing number: ~4–5 bits per cognitive event.
The Zipf Identity Proof
Here is the cleanest result in the paper. We computed the Zipf exponent — the mathematical shape of the word-frequency distribution — for both original and shuffled English.
Original English: α = −0.843, R² = 0.992.
Shuffled English: α = −0.843, R² = 0.992.
Identical. Exactly the same words at exactly the same frequencies. The Zipf distribution is preserved perfectly by shuffling.
Yet original English gives ~11 bits of effective information per token while shuffled English gives ~5 bits. Same statistics, 6 bits of difference. Word frequencies are necessary (they set the base rate) but they are not sufficient (structure determines the rest). Anyone who claims that the ~4.4-bit convergence is “just Zipf’s law” is refuted by this single control: Zipf is identical in both conditions, but information extraction is completely different.
The Energy Cost of Grammar
We expected that exploiting linguistic structure would be computationally “free” — the model runs the same forward pass regardless of whether the input is structured or random. We were wrong.
Natural language costs 0.347 millijoules per token. Shuffled language costs 0.291 millijoules per token. A 20% premium. The model works harder on structured text — probably because the attention mechanism computes meaningful long-range dependencies (subject-verb agreement, coreference, discourse coherence) that don’t exist in shuffled text.
Grammar is not free. The information it provides (~6.7 extra bits per token) costs real energy to extract (~0.056 millijoules per token, or about 0.009 millijoules per bit of structure). This is a measurable thermodynamic price for cognitive organization.
The Causal Chain
We propose — and we emphasize “propose,” because two of the four links are hypothesized rather than demonstrated — the following chain of constraint propagation:
Link 1 (Established): Physics → Biology. Thermodynamic cost minimization under pairwise discrimination constraints (Regime A, α > 1) constrains biological decoders to 3–6 bits per event. Evidence: five companion papers, the cost function derivation, the phase-space proof.
Link 2 (Established): Biology → Cognition. Neural systems built from biological substrates inherit the throughput constraint. Working memory: ~3.1 bits per item. Phoneme discrimination: ~4.2 bits. Evidence: Miller (1956), Miller & Nicely (1955), decades of psychophysics.
Link 3 (Proposed): Cognition → Language. Language evolved as a communication channel between brains constrained to ~4–5 bits per event. Speakers can only formulate ~4–5 bits of new information per utterance. Listeners can only decode ~4–5 bits per processing step. Language optimized to match. Evidence: BPT ≈ 4.4 (this paper), Shannon’s 1951 estimate, the UID literature. Not yet causally demonstrated.
Link 4 (Proposed): Language → AI. Models trained on human language learn its statistical structure. The ~4.4-bit BPT reflects the information density that biological cognition selected for. Destroy the structure (shuffling) and BPT jumps to 10.8. Evidence: the shuffling experiment. Not yet tested with a synthetic-training control.
What Would Falsify This
We offer four specific predictions, each designed to break the hypothesis if it’s wrong:
Test 1: Shuffle text from non-English languages (Chinese, Arabic, Finnish). If the ~5-bit base rate is biologically universal, all languages should show it. If only English does, the finding is language-specific, not biological.
Test 2: Train a model exclusively on non-biological data (synthetic patterns, mathematical proofs). If its BPT falls inside the 3–6 bit basin, the inherited constraint hypothesis is falsified — the basin would be a property of structured data in general, not biological data specifically.
Test 3: As models improve over generations, BPB on English should approach but not drop far below ~0.5. If frontier models achieve BPB below 0.3, the “floor” doesn’t exist.
Test 4: Languages with fewer phonemes should show steeper Zipf slopes. If no correlation exists, the basin-Zipf connection is wrong.
These predictions are offered openly and without hedging. If any of them fails, we want to know. That is how science works.
The Bigger Picture
The throughput basin constrains biology directly, through the physics of molecular discrimination. It constrains language indirectly, through the cognitive capacity of the brains that invented it. It constrains AI at one further remove, through the training data that carries language’s biological fingerprint.
The ribosome found this limit through 3.8 billion years of evolution. Human language found it through millions of years of cognitive optimization. AI learned it in a few months of training on the internet. Three timescales, three substrates, one neighborhood: ~4.4 bits.
The fingerprint is everywhere. You just have to know what to look for.
The Inherited Constraint is Paper 6 of the Windstorm series.
Zenodo: doi.org/10.5281/zenodo.19432911 ·
Code & data: github.com/Windstorm-Institute/inherited-constraint
Download the full paper (PDF)
The story does not end here. Paper 7 — The Throughput Basin Origin — takes the inherited-constraint hypothesis and tries to falsify it directly by training models on synthetic corpora with engineered information density. The result is published together with its full internal adversarial review. Read it next.
Comments & questions
Comments are powered by GitHub Discussions. Sign in with your GitHub account below, or browse all discussions on GitHub. No GitHub account? It takes 30 seconds to make one — or email Grant directly if you'd rather skip it.