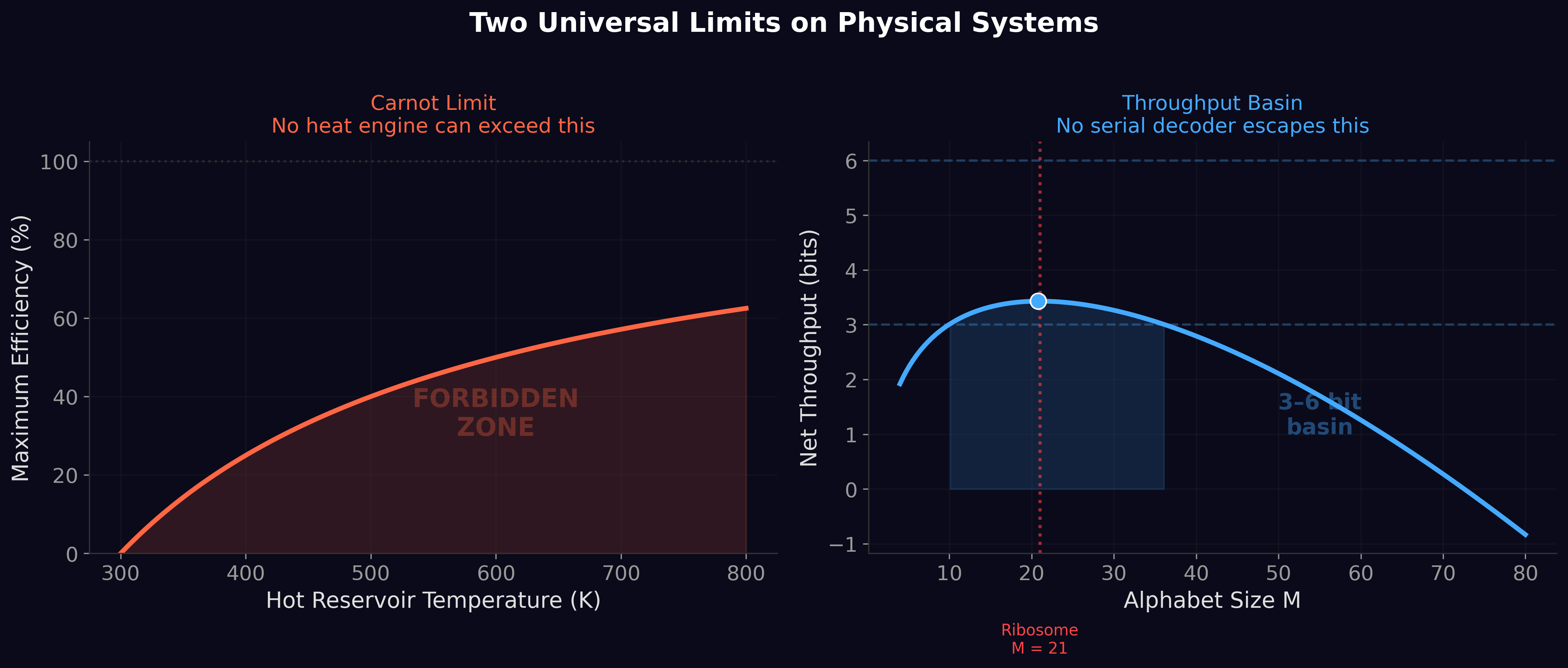
The first four papers established what the throughput basin is and where it sits. Thirty-one systems across six domains cluster between 3 and 6 bits per processing event. The ribosome was predicted to 0.003 bits from pure physics. Evolutionary simulations independently reinvented the genetic code. But one question remained unanswered: why?
Why 3–6 bits? Why not 1–2 or 10–12? What law of physics forces information processors into this specific band?
The Dissipative Decoder answers: energy. But the answer turned out to be more nuanced — and more interesting — than we expected. The basin exists for biology but not for silicon AI, and the reason reveals a fundamental architectural difference between how life and machines process information.
Two Costs That Create the Basin
Every serial decoder faces a tradeoff. Informational return — how much you learn per processing step — grows logarithmically with alphabet size. Going from 10 to 20 symbols adds about 1 bit. Going from 20 to 40 adds another. Diminishing returns.
Discrimination cost — the energy required to reliably tell one symbol from another — depends on how the system performs discrimination. And this is where biology and silicon part ways.
Regime A: How Biology Discriminates
The ribosome distinguishes amino acids through pairwise molecular recognition. Each of the 21 amino acids has a dedicated aminoacyl-tRNA synthetase — a molecular machine whose sole job is to recognize one amino acid and reject the other 20. Every new amino acid added to the alphabet requires a new synthetase that must be physically distinguished from all existing ones. The number of pairwise distinctions grows as M(M−1)/2: quadratic. At M = 21, that is 210 pairwise comparisons. At M = 30, it would be 435 — more than double the discrimination infrastructure for less than half a bit of additional information.
Plot diminishing returns against accelerating cost and the ratio — bits per joule — has a single peak. That peak sits at M ≈ 20. The genetic code has 21 amino acids because 21 is where thermodynamic efficiency is maximized. The throughput basin is the inevitable consequence of concave returns divided by convex cost.
Regime B: How Silicon Discriminates
A transformer model does not distinguish tokens through pairwise physical recognition. It performs matrix multiplication over independently learned parameters. Each parameter is a floating-point weight that contributes to a shared computation; adding one more parameter does not require comparing it to all existing ones.
The vocabulary — those 50,000+ tokens — is implemented as a cheap linear projection: the softmax layer maps a high-dimensional hidden state to a probability distribution over tokens. The cost of adding tokens to the vocabulary is negligible. This is fundamentally different from biology, where adding a symbol to the alphabet means building entirely new molecular recognition machinery.
We measured this directly. A 27-model energy benchmark on standardized Nvidia GPU hardware showed that silicon energy scales as params^0.937 — sub-linearly. Each additional parameter costs less energy than the last, not more. This is the opposite of biology’s quadratic scaling.
The consequence: no peak in bits-per-joule. No optimal vocabulary size. No thermodynamic basin. The smallest model is the most energy-efficient per bit of compression. Efficiency decreases monotonically with scale.
The Falsification That Became a Discovery
We originally predicted that energy-efficient AI models would approach the rate-distortion floor, just as the ribosome does. The data said the opposite: larger, more expensive models get closer to the floor. The prediction was cleanly falsified.
But the falsification revealed something deeper than the original prediction would have. Biology and silicon operate in fundamentally different cost regimes. Biology is alphabet-bound — its cost scales with the number of symbols it discriminates. Silicon is capacity-bound — its cost scales with the number of parameters it learns. The throughput basin is a feature of alphabet-bound systems specifically, not a universal law.
We named these Regime A (alphabet-bound, α > 1, basin exists) and Regime B (capacity-bound, α < 1, no basin). The phase-space analysis shows the basin is geometrically inevitable for any α > 1 — a topological feature of the optimization landscape, not a parameter-dependent coincidence. For α < 1, the landscape is monotonic. No basin. No peak. No constraint.
The Landauer Comparison
How far is each system from its theoretical thermodynamic minimum?
The ribosome: φ_useful ≈ 1.02. It operates within 2% of the minimum energy cost for its discrimination task. After 3.8 billion years of optimization, evolution has closed the gap almost completely.
A 7-billion-parameter transformer: approximately 800,000,000 times above its Landauer floor. Not 2%. Not 200%. Nearly a billion-fold overhead.
The ≈109 figure quoted here is the useful-dissipation fraction per discrimination event — the thermodynamically relevant energy attributed to the irreversible logical step itself. Paper 7's GPU measurements report φ ≈ 1015–1018 for total GPU wall power, which additionally pays for memory access, cooling, power-supply conversion losses, and idle leakage of the entire board. Both numbers are correct; they measure different physical boundaries. The ≈109 figure here is the right number for the computational efficiency gap; the ≈1016 figure is the right number for the total system efficiency gap. See Paper 7 §3.4 for the full reconciliation.
This single comparison says more about the difference between biological and artificial information processing than any amount of theory. Evolution is a better optimizer than human engineering — at least for serial decoding under thermodynamic constraints.
The Temperature Prediction
If discrimination cost increases with temperature (via the kT term in the Landauer bound), then organisms living at higher temperatures should show reduced amino acid diversity — they cannot afford to maintain as many distinct symbols when each distinction costs more energy.
We tested this against the live Kazusa Codon Usage Database. Twenty-nine organisms spanning 8°C to 100°C growth temperature. The partial correlation between amino acid entropy and temperature, controlling for the known GC-content confound, is r = −0.451 (p = 0.014). Heat taxes information. Hotter organisms use fewer amino acids.
This is preliminary evidence, not proof. The GC-matched control comparisons were underpowered. Phylogenetic controls (PGLS) have not yet been applied. Prior work by Singer & Hickey (2003) and Zeldovich et al. (2007) documented temperature-driven compositional shifts attributed to GC bias and protein stability. Our entropy measure captures a complementary signal, but the effect is moderate and needs confirmation.
We lead with these caveats because honest science demands them. The temperature prediction is supported, not established.
What It Means
The Dissipative Decoder answers the “why” question twice. For biology: the basin exists because pairwise molecular recognition imposes quadratic cost, and the ratio of logarithmic returns to quadratic cost has a unique peak in the 3–6 bit range. For silicon: the basin does not exist because matrix multiplication imposes sub-linear cost, and the ratio is monotonically decreasing.
Biology could not decouple its vocabulary from its discrimination cost because molecular recognition is inherently pairwise — you cannot add a new amino acid without building new molecular machinery to distinguish it from everything else. Silicon could decouple them because learned parameters are independent — a softmax projection over a 50,000-token vocabulary is cheap regardless of how many tokens you have.
This architectural difference is why biology stopped at 21 amino acids and why AI can have 50,000 tokens. It is why the ribosome operates at 98% of its thermodynamic efficiency and why GPT-4 operates at 0.0000001% of its Landauer minimum. And it is why the throughput basin constrains every biological decoder on Earth but not a single GPU.
The basin is not a universal speed limit. It is a speed limit for pairwise discriminators. Biology is one. Silicon is not. The mathematics explains both.
The Dissipative Decoder is published and available below.
The Dissipative Decoder is Paper 5 of the Windstorm series.
Zenodo: doi.org/10.5281/zenodo.19433048 ·
Code & data: github.com/Windstorm-Institute/dissipative-decoder
Download the full paper (PDF)
Comments & questions
Comments are powered by GitHub Discussions. Sign in with your GitHub account below, or browse all discussions on GitHub. No GitHub account? It takes 30 seconds to make one — or email Grant directly if you'd rather skip it.