This article summarizes "The Receiver-Limited Floor: Rate-Distortion Bounds on Serial Decoding Throughput" (Zenodo, 2026).
If you follow AI, you've heard the mantra: scale everything. More parameters. More training data. More tokens. The entire industry is built on the assumption that bigger is better.
The Receiver-Limited Floor paper tested one specific version of that assumption — that bigger vocabularies improve AI language model performance — and found it completely wrong.
The Experiment
We evaluated 1,749 language models. This is, to our knowledge, the largest tokenizer-information survey ever conducted. The models spanned two major architectures (causal language models and masked language models), vocabulary sizes from a few thousand to over 250,000 tokens, and parameter counts from millions to tens of billions.
For each model, we measured bits-per-byte (BPB) — the standard metric for how efficiently a model compresses English text. Lower BPB means better compression, which means the model understands the language better.
Then we asked: does vocabulary size predict BPB?
The Result: A Flat Line
No. The correlation between vocabulary size and BPB is essentially zero.
For causal language models: β₁ = 0.058, p = 0.643, R² = 0.007. That R² means vocabulary size explains less than 1% of the variation in model quality. The regression line is flat. A model with 32,000 tokens performs no differently from one with 128,000 tokens, all else being equal.
To put this in human terms: imagine testing whether the size of a restaurant's menu predicts the quality of the food. You survey 1,749 restaurants. The answer comes back: menu size explains 0.7% of food quality. The menu is irrelevant. What matters is the chef.
Why This Happens: The Receiver Sets the Limit
The paper explains this result using rate-distortion theory — the branch of information theory that deals with lossy compression under constraints.
The key insight is that vocabulary is a redundancy parameter, not an information parameter. Making the vocabulary bigger gives you more ways to encode the same information, but it doesn't increase the amount of information the model can extract per processing step. The bottleneck is the receiver (the model's architecture and training), not the encoding (the tokenizer).
Think of it this way: if you're trying to hear someone at a loud party, getting a bigger dictionary doesn't help. The problem isn't your vocabulary — it's the noise. The noise determines how much information you can extract per word, regardless of how many words you know.
This is exactly what Shannon's rate-distortion theory predicts. For a serial decoder processing one symbol at a time through a noisy channel, there is a floor on how much information can be extracted per event, and that floor depends on the channel characteristics (alphabet size M and error rate ε), not on the vocabulary size of the encoding.
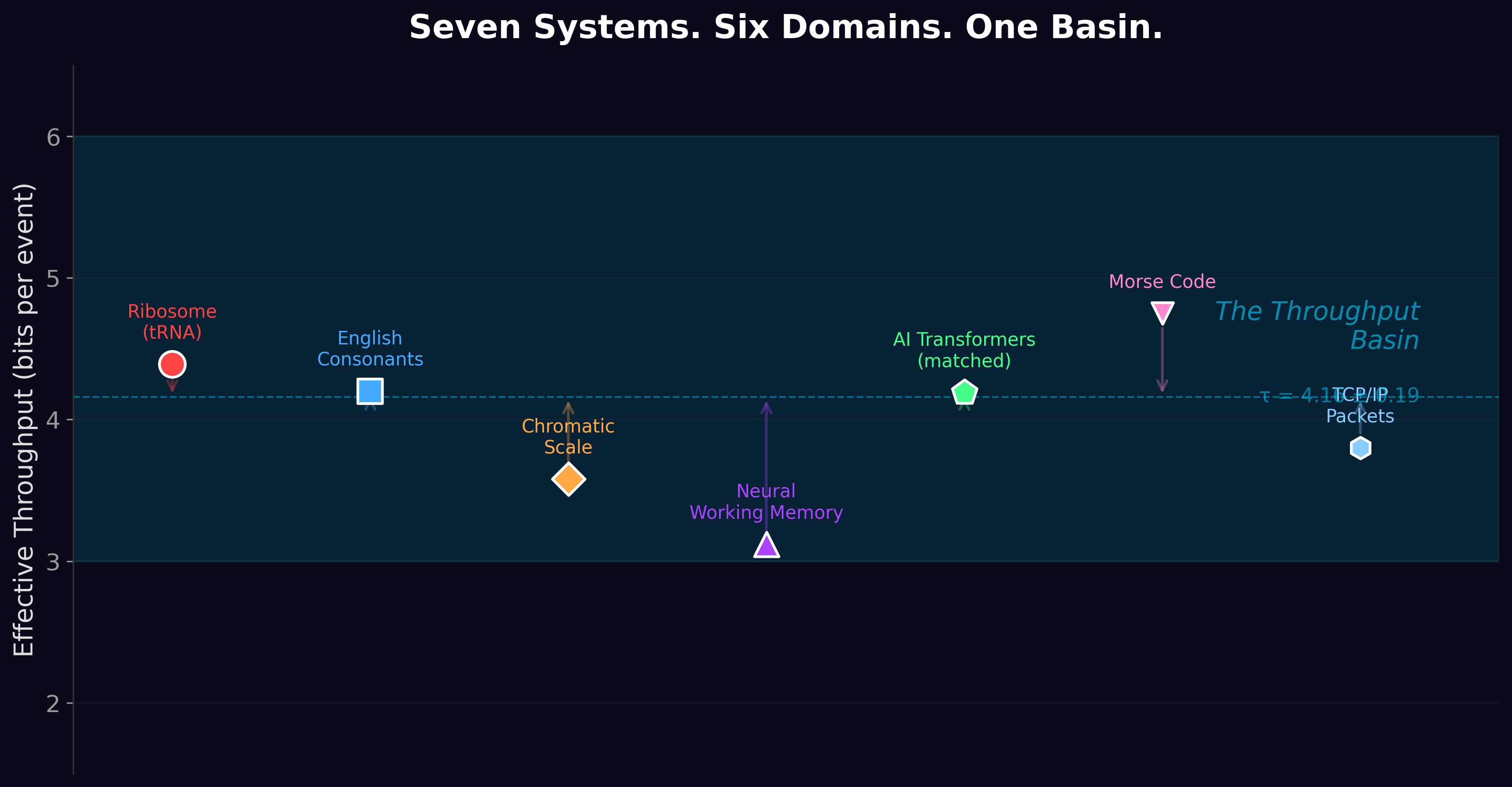
The Ribosome Connection
Here's where it gets interesting. The ribosome — the molecular machine that translates genetic code into proteins — faces the same constraint.
The ribosome's "vocabulary" is 64 codons. Its effective alphabet is 21 (20 amino acids plus stop). Its throughput is 4.39 bits per codon. Could the ribosome do better with more codons? The Fons Constraint paper showed: no. Could it do better with a completely different encoding scheme? The Receiver-Limited Floor shows: no. The floor is the floor.
AI models have vocabularies 1,000× larger than the ribosome. They have entirely different architectures, different substrates, different engineering histories. And they process about 4.2 bits of real information per token — within 5% of the ribosome.
The vocabulary doesn't matter. The receiver does. And both receivers — biological and silicon — hit approximately the same limit.
What This Means for AI Engineering
If you're building AI systems, the practical implication is immediate: stop investing in vocabulary optimization and start investing in architecture efficiency.
Every dollar spent on tokenizer engineering (merging strategies, byte-pair encoding variants, sentencepiece vs. tiktoken) is a dollar that could have gone toward architectural improvements that actually move the needle. The data says vocabulary is a solved problem at any reasonable size. The unsolved problem is making each processing step extract more real information — and the Receiver-Limited Floor suggests there may be a fundamental limit on that too.
For AI hardware: the finding extends to energy cost. In a follow-up analysis, we showed that vocabulary size also doesn't predict energy-per-token (p = 0.818, R² = 0.001). What predicts energy cost is model parameter count. What predicts compression quality is also model parameter count (and architecture quality). Vocabulary size predicts neither.
The message for GPU designers and data center operators is the same as for model developers: the bottleneck is the receiver's efficiency, not the encoding's granularity. Optimize joules per decision, not tokens per second.
The Deeper Lesson
The Receiver-Limited Floor was the second paper to show that information processing converges on the same constraints regardless of substrate. The genetic code uses 64 codons and gets 4.4 bits. AI uses 50,000 tokens and gets 4.2 bits. A 750× difference in vocabulary produces a 5% difference in throughput.
The rate-distortion surface doesn't care about your vocabulary. It cares about your noise and your discrimination cost. That realization drove us to ask: how many other systems hit this same wall? The answer is in Paper 3.
The BPT values reported here — roughly 4.2 bits/token across the 1,749-model catalog, and the apparent match to the ribosome’s 4.4 bits/codon — are measured in bits per BPE token, not bits per source symbol. The internal adversarial review of Paper 7 identified that BPT measurements are tokenizer-dependent: the same model on the same corpus returns different BPT values under different tokenization schemes. The numerical alignment with the ribosomal floor is therefore at the level of “both systems land in the same narrow bit-per-event regime,” not an exact match at the source-symbol level. A bits-per-source-symbol re-measurement across the 1,749-model catalog is now scoped under Paper 7.1.
The directional finding — that 1,749 models spanning three orders of magnitude in vocabulary all land in a narrow throughput band rather than spreading across the possible range — is not affected by the unit choice. Paper 7 then established that the band’s width itself is data-driven: source entropy minus the structure a decoder can exploit.
The Receiver-Limited Floor is Paper 2 of the Windstorm series.
Zenodo: doi.org/10.5281/zenodo.19322973 ·
Code & data: github.com/Windstorm-Institute/receiver-limited-floor
Download the full paper (PDF)
Comments & questions
Comments are powered by GitHub Discussions. Sign in with your GitHub account below, or browse all discussions on GitHub. No GitHub account? It takes 30 seconds to make one — or email Grant directly if you'd rather skip it.